
My First Homelab
Back in the fall of 2019, I was a recent college grad working my first year as a science teacher in the Southern United States. Understanding my career choice, my chosen subject, my location, and the time frame, you can likely put together why I now work in IT and live in the Midwest. Add an angry mob, some pitch forks, and some torches, and your imagination will match reality pretty closely. While both of my parents were software engineers, and my minor was in computer science, I didn’t really have any hands-on experience that I could leverage to get a job in IT. That’s where a $50 Dell Optiplex 7010 with a 3rd gen Intel i5 I found on Facebook marketplace saves the day.
In my new one-device homelab, that machine initially ran a trial version of Windows Server 2019 which is how I learned active directory and other windows server and endpoint administration skills. I wiped that machine several times to try out other operating systems. Because I seriously didn’t understand what I was doing, I settled on desktop Ubuntu and ran my VMs in virtualbox. Every time I reset that machine, I had to VNC into the desktop environment and turn on the virtualbox VMs manually. It was slow, clunky, over-provisioned beyond reason, but it served it’s purpose. I got a job in IT thanks to the questionable skills I learned on that even more questionable setup.
Flash forward to today, that machine is still in my lab and runs bare metal OPNsense. I have a far more powerful box running proxmox for general virtualization purposes.
Declaring Bankruptcy
Unfortunately my habit of solving a problem without fully understanding the solution continued. I’m in a better state now running proxmox and using a proper tested backup system. However, there are still some interesting choices that I made along the way, which I would absolutely do different with the knowledge I have now. After two outages in the last month caused by some of those interesting choices, I’ve decided it’s time to stop limping along the system as is, go back to the drawing board, and set everything up from scratch. This post will serve as an analysis of my current state, and the starting point for for what I’d like to move to.
Analysis
DNS and DHCP
There is no excuse for the current state of my DNS: its messed up. My current DNS system is what happens when you experiment in prod and then decide you can’t be bothered to revert. I have four LXCs running pihole. Yes, you read that right I’m running four piholes.
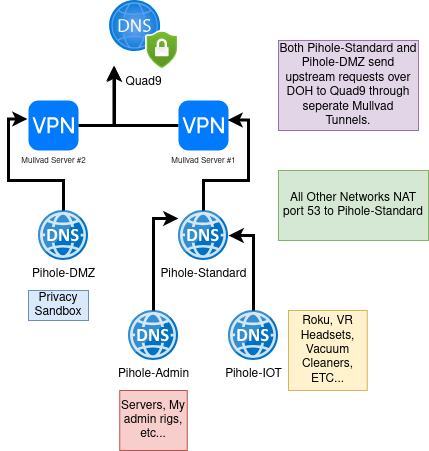
Why? Well, it started because for some reason I decided my threat model included people on my local network even knowing the IP address of anything but the reverse proxy even if they’re blocked by the firewall. Why? I dunno.
So I have my pihole-standard which is available to anyone on the main wifi channel, which only points to the reverse proxy and serves other upstream requests. For my servers, I have pihole-admin which includes manually added and maintained entries with the IP addresses of all of my servers, LXCs, and VMs. Pihole-admin forwards all other requests up to pihole-standard, which then forwards them out to the internet. Yes, I daisy-chained them together for some reason.
I also have pihole-iot for iOT devices which maintains a 100% blocklist with only certain domains whitelisted (e.g. api.rokutime.com, because Roku can’t be bothered to use NTP and has to encrypt these requests in their own silly API). The DNS level blocking on the iOT network adds some suspenders to the belt I’m already wearing by blocking all IPs in OPNsense except those specifically whitelisted by me. I’m then running a pihole-dmz for my privacy sandbox VMs for absolutely no reason other than I thought it should have it’s own at some point.
All of this unneeded complexity means that my OPNsense box is not authoritative for hostnames. It also means that even though I may have a DHCP reservation set, I still need to do some manual work to get a device to resolve in DNS when I set up a new service. This complicated setup also means if my proxmox server goes down, everyone loses internet and significantly impacts the spouse approval factor of the lab. All of this should be managed in one place and automated as best as possible. In the next iteration of my lab it’s going to all be handled by Unbound DNS in OPNsense.
Reverse Proxy
I am pretty proud of my reverse proxy setup, though I’m not proud of what got me here. When I got it working a few years ago, I didn’t know that nice GUI solutions like Caddy or NGINX Proxy Manager existed, so I’m running an LXC with barebones nginx conf files that I’ve manually tuned for each service I use. To automate my SSL, I’m using Dehydrated to automate a DNS-01 challenge to renew my Let’s Encrypt certs and it’s never failed me once.
That said, in my next state I think moving to something like NPM or Caddy is the move I’ll make. Raw Nginx conf files are great for understanding how a reverse proxy works, but they’re not so great for general maintenance of a homelab once you have that knowledge. Moving to NPM or Caddy will allow me to automate issuing SSL for new docker containers since they support hooking them up to the docker socket directly to detect those services automatically. Which would allow me to be more flexible in changing my configuration in the future.
Up-to-date Applications
I value stability over anything in my self-hosted services (feel free to laugh if you read the DNS section), which is what pushed me to deploy Debian 12 for all of my VMs and LXCs. Unfortunately, I realized recently that on some of my machines I went out of my way to add the proper apt repositories to use the most up to date versions of tools like Docker and Nginx, but on others I forgot and I’m using the ancient versions in the standard Debian apt repo. This has resulted in some confusion when I’m troubleshooting, and in me building workarounds for solved problems on newer versions of those tools.
I would love to move to something like Ubuntu to have more up to date packages. Unfortunately, I’m one of those people who is a little unhappy about the whole Snap situation, so Debian will remain my server OS of choice (I run Arch on desktop, btw). However, what I can do during this re-work is double and triple check all of my VMs and LXCs to ensure I’m using the most up to date versions of tools where it matters, and also document where I’ve decided the stable version is fine.
Filesystems and Backups
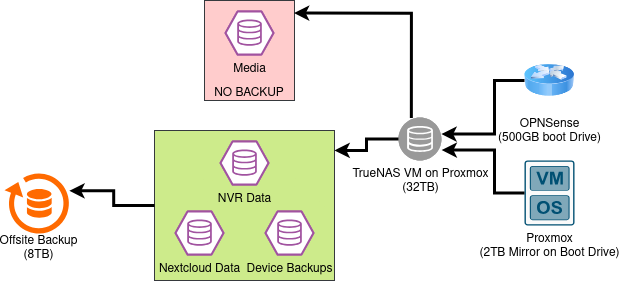
Thankfully, for the past two years I’ve had a proper 3-2-1 backup thanks to an off-site ZFS device at a friend’s home which I verify occasionally. I’ve recently switched to 100% ZFS in my entire lab. My hypervisor and router are both running ZFS on root and that’s made replication a breeze and I don’t plan on changing this. I am however running TrueNAS Scale in a VM on promox by passing through an HBA with some spinning rust disks, which has proven to be less than ideal as you might imagine. As has my decision early on to encrypt the entire ZFS pool. This means I cannot set several of my VMs to auto-start on a reboot of my proxmox node because I need to go in to Truenas and enter my encryption password to unlock the pool before turning on the VMs that use those shares.
Oh, and the above diagram is a simplification of what I’ve got going on. Here’s a dump of the fstab on my proxmox server to give you a more accurate idea of the sprawl I’m experiencing.
| |
In the next iteration of my lab, I am going to remove things like my media library, and backups that are already encrypted in their own right from the ZFS encryption for my own sanity. Things like my Nextcloud Data I will likely continue encrypting since my threat model does currently include physical theft. I’ll just have to accept that I will need to unlock the pool every time the system boots to use those shares, but that’s far less of a chore than doing that for literally all of my systems which is my current state. I’d also like to separate my main ZFS shares from my hypervisor but that may not be in the cards financially at the moment.
Notifications
My current notification system for server outages is my fiancé. Unfortunately, it’s rather hard to mute those alerts, and depending on the severity of the outage I tend to get a lot of duplicate notices. I’ve filed an issue with the developer but they’ve told me they’re no longer maintaining the project, but that I’m welcome to fork it. I think the best option might be to migrate to another project entirely, but when I mentioned this to the developer I was uninvited from Thanksgiving dinner.
Due to my annual requirement for turkey and cranberry sauce, I’ll need to spin up a separate notification system to catch alerts before they turn into outages. I’ve heard Ntfy is good for this, but I haven’t looked too hard quite yet.
Remote Access
Now that my family has seen some of the things I’ve done with my lab, a couple of them have asked for access to things like my media server or Nextcloud. Right now, I’m facilitating this with a wireguard VPN that points to a dynamic DNS address, and I send them a separate config for each device they want to hook up and I walk them through the process manually. Those lucky souls who host a backup for me, get a gateway to those services on their LAN included as a thank you. All I do is spin up reverse proxy and a pihole on that box, serve it as their DNS, and have the proxy send requests for my server back over my VPN connection on the backup box.
All that being said, I’ve experimented briefly with Tailscale, and I like it. I think it’s going to be the solution for onboarding my non-techy family (well, as non-techy as the children of two software engineers can be) into my ecosystem. Though I may go with a headscale server on a VPS personally just to keep it 100% self-hosted.
Next Steps
Well, after marking all that down in… erm… markdown… it suddenly doesn’t seem like a whole heck of a lot. Quite a few quality of life improvements, but nothing unreasonable or unapproachable. This doesn’t necessarily require a full reset of my entire lab, but at this point I think just for cleanliness sake, that’s what I should do. A full reset will help me fix some of the file share and DNS sprawl right from the beginning. I’ll report back in awhile with how this all goes. Happy labbing!